Building Scalable API Backends with Covalent for LLM and Generative AI Applications#
In this tutorial, we’ll delve into the intricacies of constructing scalable API backends for Large Language Models (LLMs) and Generative AI applications. We aim to facilitate seamless collaboration between two cornerstone roles in contemporary machine learning projects: researchers, who innovate and experiment with models, and engineers, tasked with transforming these models into production-grade applications.
Navigating the deployment of high-compute API endpoints, particularly for Generative AI and LLMs, often presents a myriad of challenges. From juggling multiple cloud resources to managing operational overheads and switching between disparate development environments, the endeavor can quickly escalate into a complex ordeal. This tutorial is designed to guide you through these hurdles using Covalent, a Pythonic workflow orchestration platform.
Key Challenges and how Covalent solves them#
Resource Management: The manual management of cloud resources like GPUs is not only tedious but also prone to errors. Covalent automates this, allowing for smooth workflow management right from your Python environment.
Operational Overhead: Tasks like maintaining server uptime, load balancing, and API versioning can complicate the development process. Covalent streamlines these operational aspects, freeing you to focus on development.
Environment Switching: The need to switch between development, testing, and production environments can be a bottleneck, especially in agile, iterative development cycles. Covalent offers a unified environment, simplifying this transition.
Multi-Cloud Deployment: With GPUs often in short supply, the ability to deploy across multiple cloud providers is increasingly crucial. Covalent supports multi-cloud orchestration, making this usually complex task straightforward.
Scalability: High-compute tasks often require dynamic scaling, which can be cumbersome to manage manually. Covalent handles this automatically, adapting to the computational needs of your project.
Tutorial overview#
This tutorial will encompass the following steps:
Developing a customizable Covalent workflow designed to employ AI for news article summarization [researcher],
Executing experiments on the established Covalent workflows iteratively, aiming for desirable performance outcomes [researcher], and
Rerunning and reusing experiments via the Streamlit application [engineer]
Getting started#
This tutorial requires PyTorch, Diffusers, Hugging Face Transformers for generative AI. Streamlit will serve to make the user experience smooth. To install all of them, simply use the requirements.txt file to replicate this notebook.
The list of packages required to run this tutorial is listed below.
[2]:
with open("./requirements.txt", "r") as file:
for line in file:
print(line.rstrip())
accelerate==0.21.0
bs4==0.0.1
covalent-azurebatch-plugin==0.12.0
diffusers==0.19.3
emoji==2.8.0
Pillow==9.5.0
sentencepiece==0.1.99
streamlit==1.25.0
torch==2.0.1
transformers==4.31.0
xformers==0.0.21
[3]:
# Uncomment below line to install necessary libraries
# !pip install requirements.txt
[6]:
# save under workflow.py
import os
import re
import requests
from uuid import uuid4
from bs4 import BeautifulSoup
import transformers
from transformers import (
AutoTokenizer, T5Tokenizer, T5ForConditionalGeneration,
pipeline, AutoModelForSequenceClassification
)
from diffusers import DiffusionPipeline
from PIL import Image, ImageDraw, ImageFont
import covalent as ct
import torch
import logging
News Summarization workflow#
We first define executors to use Azure Batch as compute. Two types of executors allow us to leverage different executors for different compute
[7]:
# save under workflow.py
# setting loggers to info to avoid too many debug messages
loggers = [logging.getLogger(name) for name in logging.root.manager.loggerDict]
for logger in loggers:
logger.setLevel(logging.INFO)
# define dependencies to install on remote execution
DEPS_ALL = ct.DepsPip(
packages=[
"transformers==4.31.0", "diffusers==0.19.3", "accelerate==0.21.0",
"cloudpickle==2.2.0", "sentencepiece==0.1.99", "torch==2.0.1",
"Pillow==9.5.0", "xformers==0.0.21", "emoji==2.8.0", "protobuf"
]
)
azure_cpu_executor = ct.executor.AzureBatchExecutor(
# Ensure to specify your own Azure resource information
pool_id="covalent-cpu",
retries=3,
time_limit=600,
)
# base_image_uri points to a non-default different docker image to support use nvidia gpu
azure_gpu_executor = ct.executor.AzureBatchExecutor(
# Ensure to specify your own Azure resource information
pool_id="covalent-gpu",
retries=3,
time_limit=600,
base_image_uri="docker.io/filipbolt/covalent_azure:0.220.0",
)
Each electron is associated with an executor, where the computation takes place. Within this framework, less demanding tasks are allocated to the cpu executor, while computationally intensive tasks, like generating images from textual prompts, are designated to the gpu for compute resources. First, we provide the task outlines.
[5]:
# save under workflow.py
@ct.electron(executor=azure_cpu_executor)
def extract_news_content(news_url):
response = requests.get(news_url)
soup = BeautifulSoup(response.content, "html.parser")
# Extracting article text
paragraphs = soup.find_all("p")
article = " ".join([p.get_text() for p in paragraphs])
return article
@ct.electron(executor=azure_cpu_executor)
def generate_title(
article, model_name="JulesBelveze/t5-small-headline-generator",
max_tokens=84, temperature=1, no_repeat_ngram_size=2
):
...
@ct.electron(executor=azure_gpu_executor)
def generate_reduced_summary(
article, model_name="t5-small", max_length=30
):
...
@ct.electron(executor=azure_cpu_executor)
def add_title_to_image(image, title):
...
@ct.electron(executor=azure_gpu_executor)
def sentiment_analysis(
article, model_name="finiteautomata/bertweet-base-sentiment-analysis"
):
...
@ct.electron(executor=azure_cpu_executor)
def generate_image_from_text(
reduced_summary, model_name="OFA-Sys/small-stable-diffusion-v0", prompt="Impressionist image - "
):
...
@ct.electron(executor=azure_cpu_executor)
def save_image(image, filename='image'):
...
The workflow connects all these steps (electrons) into a workflow (lattice) into a cohesive and runnable workflow.
[6]:
# save under workflow.py
@ct.lattice
def news_content_curator(
news_url, image_generation_prefix="Impressionist image ",
summarizer_model="t5-small",
summarizer_max_length=40,
title_generating_model="JulesBelveze/t5-small-headline-generator",
image_generation_model="OFA-Sys/small-stable-diffusion-v0",
temperature=1, max_tokens=64, no_repeat_ngram_size=2,
content_analysis_model="finiteautomata/bertweet-base-sentiment-analysis"
):
article = extract_news_content(news_url)
content_property = sentiment_analysis(
article, model_name=content_analysis_model
)
reduced_summary = generate_reduced_summary(
article, model_name=summarizer_model, max_length=summarizer_max_length
)
title = generate_title(
article, model_name=title_generating_model,
temperature=temperature, max_tokens=max_tokens,
no_repeat_ngram_size=no_repeat_ngram_size
)
generated_image = generate_image_from_text(
reduced_summary, prompt=image_generation_prefix,
model_name=image_generation_model
)
image_with_title = add_title_to_image(generated_image, title)
url = save_image(image_with_title)
return {
"content_property": content_property, "summary": reduced_summary,
"title": title, "image": url,
}
Finally, once a lattice is defined, you must dispatch a workflow to run it. You can dispatch a lattice workflow using Covalent by calling ct.dispatch and providing a workflow name and parameters.
[8]:
news_url = 'https://www.quantamagazine.org/math-proof-draws-new-boundaries-around-black-hole-formation-20230816/'
dispatch_id = ct.dispatch(news_content_curator)(news_url)
print(dispatch_id)
36d7f373-705a-46d6-8ac5-ed57cac8e332
The resulting workflow should look like the example below

Now that the workflow successfully runs, we add more logic to the stub tasks we previously built.
Generating text, images, and analyzing content via sentiment analysis can all be implemented via the transformers and diffusers frameworks:
[9]:
# place in workflow.py
@ct.electron(executor=azure_gpu_executor, deps_pip=DEPS_ALL)
def generate_title(
article, model_name="JulesBelveze/t5-small-headline-generator",
max_tokens=84, temperature=1, no_repeat_ngram_size=2
):
WHITESPACE_HANDLER = lambda k: re.sub("\s+", " ", re.sub("\n+", " ", k.strip()))
if 't5' in model_name:
tokenizer = T5Tokenizer.from_pretrained(
model_name, legacy=False
)
else:
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
# Process and generate title
input_ids = tokenizer(
[WHITESPACE_HANDLER(article)], return_tensors="pt",
padding="max_length", truncation=True, max_length=384,
)["input_ids"]
output_ids = model.generate(
input_ids=input_ids, max_length=max_tokens,
no_repeat_ngram_size=no_repeat_ngram_size, num_beams=4,
temperature=temperature
)[0]
return tokenizer.decode(output_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
@ct.electron(executor=azure_gpu_executor, deps_pip=DEPS_ALL)
def generate_reduced_summary(
article, model_name="t5-small", max_length=30
):
if 't5' in model_name:
tokenizer = AutoTokenizer.from_pretrained(model_name + "_tokenizer", legacy=False)
else:
tokenizer = T5Tokenizer.from_pretrained(model_name + "_tokenizer")
model = T5ForConditionalGeneration.from_pretrained(model_name)
# Encode the article and generate a title
input_text = "summarize: " + article
inputs = tokenizer.encode(
input_text, return_tensors="pt", max_length=512, truncation=True
)
# Generate a title with a maximum of max_length words
outputs = model.generate(inputs, max_length=max_length, num_beams=4, length_penalty=2.0, early_stopping=True)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
@ct.electron(executor=azure_gpu_executor, deps_pip=DEPS_ALL)
def sentiment_analysis(
article,
model_name="finiteautomata/bertweet-base-sentiment-analysis"
):
sentiment_pipeline = pipeline(
"sentiment-analysis", model=model_name,
padding=True, truncation=True
)
mapping = {
'NEU': 'neutral',
'NEG': 'negative',
'POS': 'positive'
}
label = sentiment_pipeline(article)[0]["label"]
return mapping.get(label, label)
@ct.electron(executor=azure_gpu_executor, deps_pip=DEPS_ALL)
def generate_image_from_text(reduced_summary, model_name="OFA-Sys/small-stable-diffusion-v0", prompt="Impressionist image - "):
model = DiffusionPipeline.from_pretrained(
model_name, safety_checker=None,
torch_dtype=torch.float16
)
model.enable_attention_slicing()
# Generate image using DiffusionPipeline
reduced_summary = prompt + reduced_summary
_ = model(reduced_summary, num_inference_steps=1)
return model(reduced_summary).images[0]
The generated images and text can be patched together, and the image may then be uploaded to a cloud storage to make it easier to transfer it via an API.
[10]:
@ct.electron(executor=azure_cpu_executor, deps_pip=DEPS_ALL)
def add_title_to_image(image, title):
# Create a new image with space for the title
new_image = Image.new(
"RGB", (image.width, image.height + 40), color="black"
)
new_image.paste(image, (0, 40))
# Create a drawing context
draw = ImageDraw.Draw(new_image)
font = ImageFont.load_default()
# Sanitize title to remove non-latin-1 characters
sanitized_title = "".join([i if ord(i) < 128 else " " for i in title])
# Split the title into multiple lines if it's too long
words = sanitized_title.split()
lines = []
while words:
line = ""
while words and font.getlength(line + words[0]) <= image.width:
line += words.pop(0) + " "
lines.append(line)
# Calculate position to center the text
y_text = 10
for line in lines:
# Calculate width and height of the text to be drawn
_, _, width, height = draw.textbbox(xy=(0, 0), text=line, font=font)
position = ((new_image.width - width) / 2, y_text)
draw.text(position, line, font=font, fill="white")
y_text += height
return new_image
Finally, we will upload the save the image to our local machine and transfer it to Streamlit.
[11]:
@ct.electron
def save_image(image, filename='image'):
image.save(f"{filename}.jpg")
return image
Rerunning Workflows#
Upon the execution of a Covalent workflow, an associated dispatch_id is generated, serving as a unique workflow execution identifier. This dispatch ID serves a dual purpose: it acts as a reference point for the specific workflow and also facilitates the rerun of the entire workflow. Covalent retains a record of all previously executed workflows in a scalable database, thus forming a comprehensive history that can be rerun using their respective dispatch IDs.
Redispatching a workflow to summarize a different news article can be done by providing the dispatch_id to the redispatch method:
[12]:
new_url = "https://www.quantamagazine.org/what-a-contest-of-consciousness-theories-really-proved-20230824/"
redispatch_id = ct.redispatch(dispatch_id)(new_url)
print(redispatch_id)
eb54ecee-1eea-4e96-aca3-a75dd64ba677
It’s important to distinguish between dispatching workflows (using ct.dispatch) and redispatching them (using ct.redispatch). Dispatching is typically carried out during the stages of designing a new workflow, while redispatching involves replicating and refining a previously created and dispatched workflow.
It’s also possible to rerun a workflow while reusing previously computed results. For instance, if you want to experiment with a different prompt for generating images from the same news article, while keeping the summarization and headline generation unchanged, you can initiate the workflow again, preserving the use of previous results:
[13]:
redispatch_id = ct.redispatch(dispatch_id, reuse_previous_results=True)(new_url, "Cubistic image")
Furthermore, it’s possible to tailor a previously executed workflow by replacing tasks. We can achieve this by employing the replace_electrons feature, which allows us to substitute one task with another.
[10]:
@ct.electron(executor=azure_cpu_executor)
def classify_news_genre(
article, model_name="abhishek/autonlp-bbc-news-classification-37229289"
):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
inputs = tokenizer(
article, return_tensors="pt", truncation=True, max_length=512
)
outputs = model(**inputs)
id2label = {
0: "business",
1: "entertainment",
2: "politics",
3: "sport",
4: "tech"
}
return id2label[outputs.logits.argmax().item()]
replace_electrons = {
"sentiment_analysis": classify_news_genre
}
redispatch_id = ct.redispatch(dispatch_id, replace_electrons=replace_electrons)(
new_url, "Cubistic image", content_analysis_model="abhishek/autonlp-bbc-news-classification-37229289"
)
print(redispatch_id)
Rerunning workflows via Streamlit#
Now, let’s proceed with the process of constructing the Streamlit app. This app will function as a gateway to Covalent, automatically initializing the Covalent server if it hasn’t been started already, and commencing the initial workflow. Subsequently, new workflows will be triggered based on this initial one.
At this point, we recommend to decouple the python code into two files: 1. workflow.py containing the code defining and running the Covalent workflow 2. streamlit_app.py containing Streamlit code
[15]:
# add to streamlit_app.py
import streamlit as st
import covalent as ct
from subprocess import check_output
import subprocess
def is_covalent_down():
out = check_output(["covalent", "status"])
if "Covalent server is stopped" in out.decode('utf-8'):
return True
return False
def run_covalent_workflow(workflow_filename):
dispatch_id = check_output(["python", workflow_filename]).decode("utf-8")
return dispatch_id.strip()
def start_covalent():
subprocess.run("covalent start --no-cluster", shell=True)
if is_covalent_down():
st.write("Covalent is not up. Starting Covalent...")
start_covalent()
if check_google_creds():
# execute a covalent workflow
dispatch_id = run_covalent_workflow("workflow_remote.py")
# wait for result
ct.get_result(dispatch_id, wait=True)
st.session_state['dispatch_id'] = dispatch_id
Now, the Streamlit app will automatically start Covalent server and launch the first workflow. You may also directly then reuse the dispatch_id of the launched workflow to start rerunning workflows and iterating with experiments on tweaking the workflow.
Now that we have the capability to execute and re-execute Covalent workflows, our goal is to offer users a user-friendly interface. Streamlit enables us to achieve precisely that! We have developed a compact Streamlit application that enables users to adjust parameters for the AI news summarization workflow mentioned earlier and trigger previously executed workflows using their dispatch IDs. The sidebar of the Streamlit app will contain the parameters, with some proposed default values, whereas the central part of the Streamlit app will serve to render the results of the Covalent workflows.
The Streamlit sidebar can be defined as:
[16]:
# add to streamlit_app.py
def create_streamlit_sidebar(
stable_diffusion_models, news_summary_generation,
headline_generation_models, sentiment_analysis_models,
genre_analysis_models
):
with st.sidebar:
news_article_url = st.text_input(
"News article URL",
value="https://www.quantamagazine.org/math-proof-draws-new-boundaries-around-black-hole-formation-20230816/"
)
st.header("Parameters")
# Title generation section
st.subheader("Title generation parameters")
title_generating_model = headline_generation_models[0]
temperature = st.slider(
"Temperature", min_value=0.0, max_value=100.0, value=1.0,
step=0.1
)
max_tokens = st.slider(
"Max tokens", min_value=2, max_value=50, value=32,
)
# Image generation section
st.subheader("Image generation")
image_generation_prefix = st.text_input(
"Image generation prompt",
value="impressionist style"
)
image_generation_model = stable_diffusion_models[0]
# Text summarization section
st.subheader("Text summarization")
summarizer_model = news_summary_generation[0]
summarizer_max_length = st.slider(
"Summarization text length", min_value=2, max_value=50, value=20,
)
# Content analysis section
st.subheader("Content analysis")
selected_content_analysis = st.selectbox(
"Content analysis option", options=[
"sentiment analysis",
"genre classification"
]
)
if selected_content_analysis == "sentiment analysis":
content_analysis_model = sentiment_analysis_models[0]
else:
content_analysis_model = genre_analysis_models[0]
return {
'news_url': news_article_url,
'image_generation_prefix': image_generation_prefix,
'summarizer_model': summarizer_model,
'summarizer_max_length': summarizer_max_length,
'title_generating_model': title_generating_model,
'image_generation_model': image_generation_model,
'temperature': temperature,
'max_tokens': max_tokens,
'content_analysis_model': content_analysis_model,
'selected_content_analysis': selected_content_analysis
}
The central part of the Streamlit app is designed to render results from Covalent server, using the parameters configured in the sidebar. This triggers the generation of an AI-generated summary of the news article, a proposed title, and an AI-generated image depicting the content of the news article.
[19]:
# add to streamlit_app.py
st.title("News article AI summarization")
dispatch_id = st.text_input("Dispatch ID")
if st.button("Generate image and text summary"):
st.write("Generating...")
container = st.container()
# select either genre analysis or sentiment analysis
selected_content_analysis = parameters.pop('selected_content_analysis')
if selected_content_analysis != 'sentiment analysis':
replace_electrons = {
"sentiment_analysis": ct.electron(classify_news_genre)
}
parameters[
"content_analysis_model"
] = "abhishek/autonlp-bbc-news-classification-37229289"
else:
replace_electrons = {}
redispatch_id = ct.redispatch(
dispatch_id, reuse_previous_results=True,
replace_electrons=replace_electrons
)(**parameters)
covalent_info = ct.get_config()['dispatcher']
address = covalent_info['address']
port = covalent_info['port']
covalent_url = f"{address}:{port}/{redispatch_id}"
st.write(f"Covalent URL on remote server: http://{covalent_url}")
with container:
result = ct.get_result(redispatch_id, wait=True).result
st.subheader(f"Article generated title: {result['title']}")
st.write(
"In terms of " +
selected_content_analysis +
" content is: " + str(result['content_property'])
)
st.image(result['image'])
st.text_area(
label="AI generated summary",
key="summary",
value=result['summary'], disabled=True
)
If you saved the provided streamlit code in streamlit_app.py, you can run it in a separate python console by running
streamlit run streamlit_app.py
This will start the streamlit app on http://localhost:8501
You can use the streamlit app as demonstrated below:
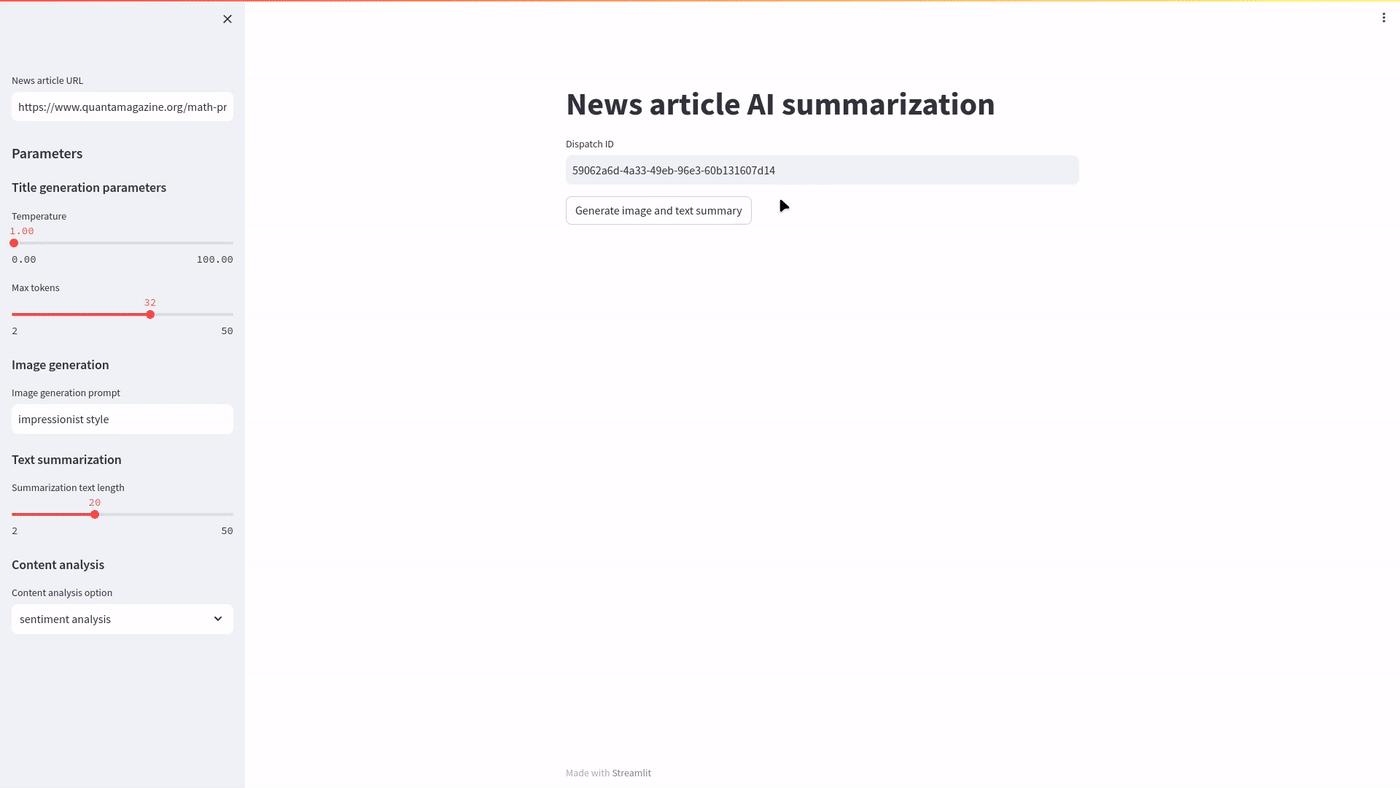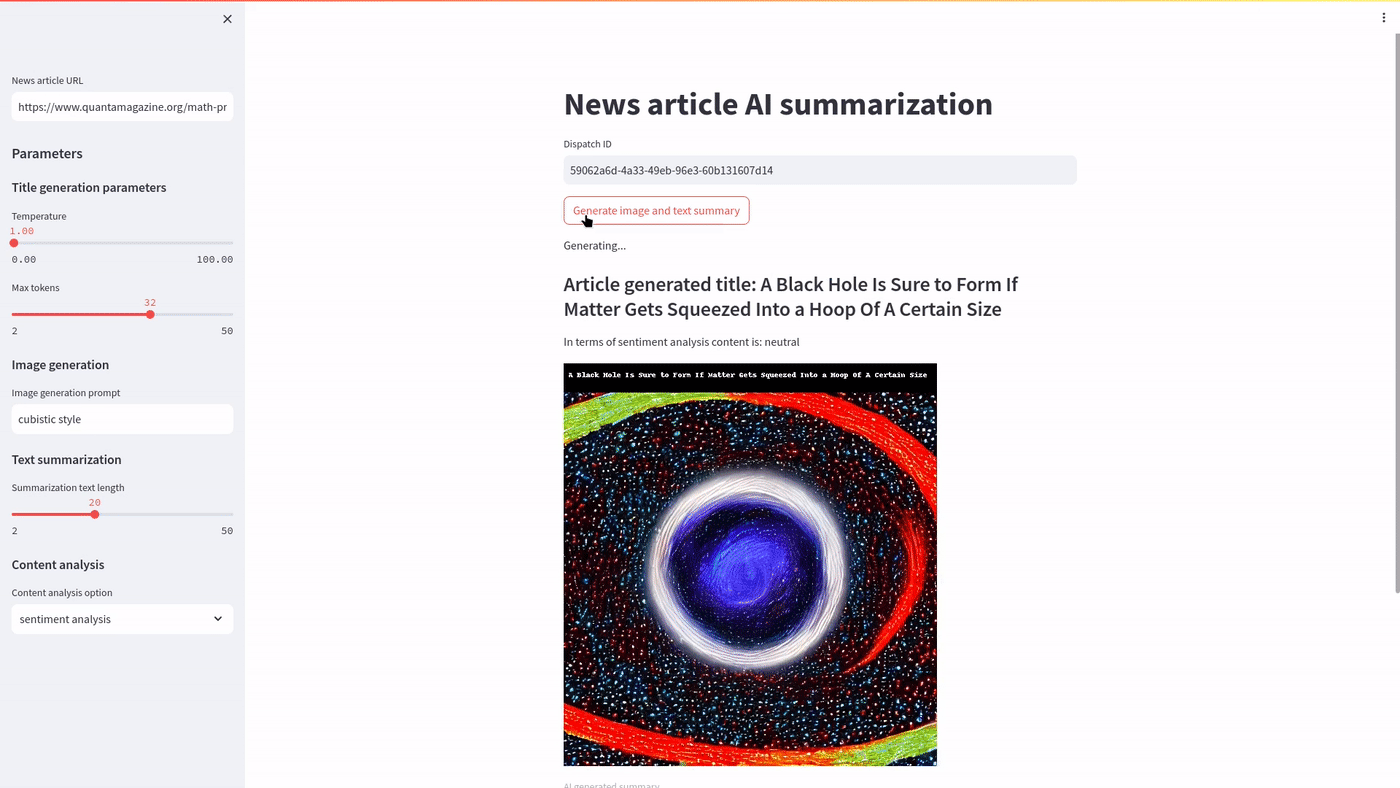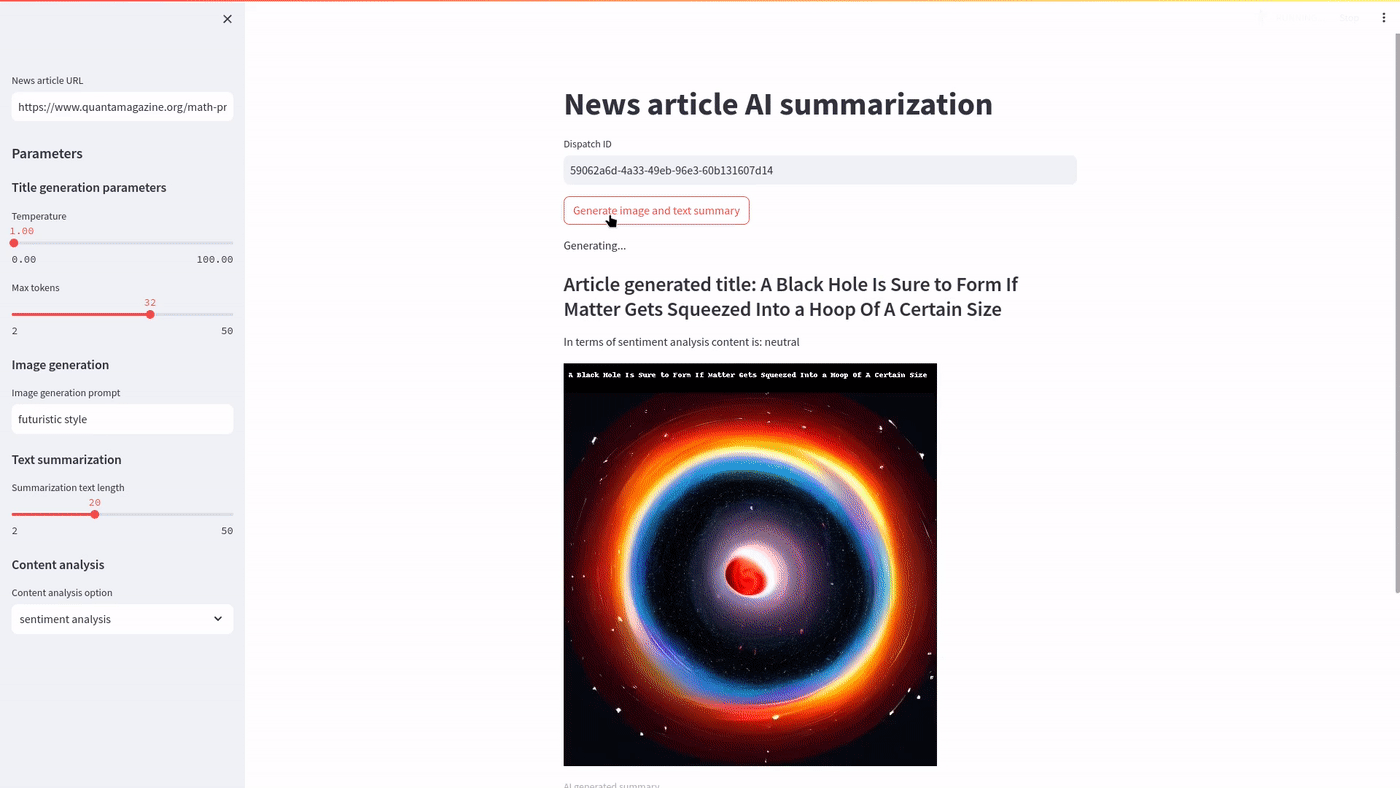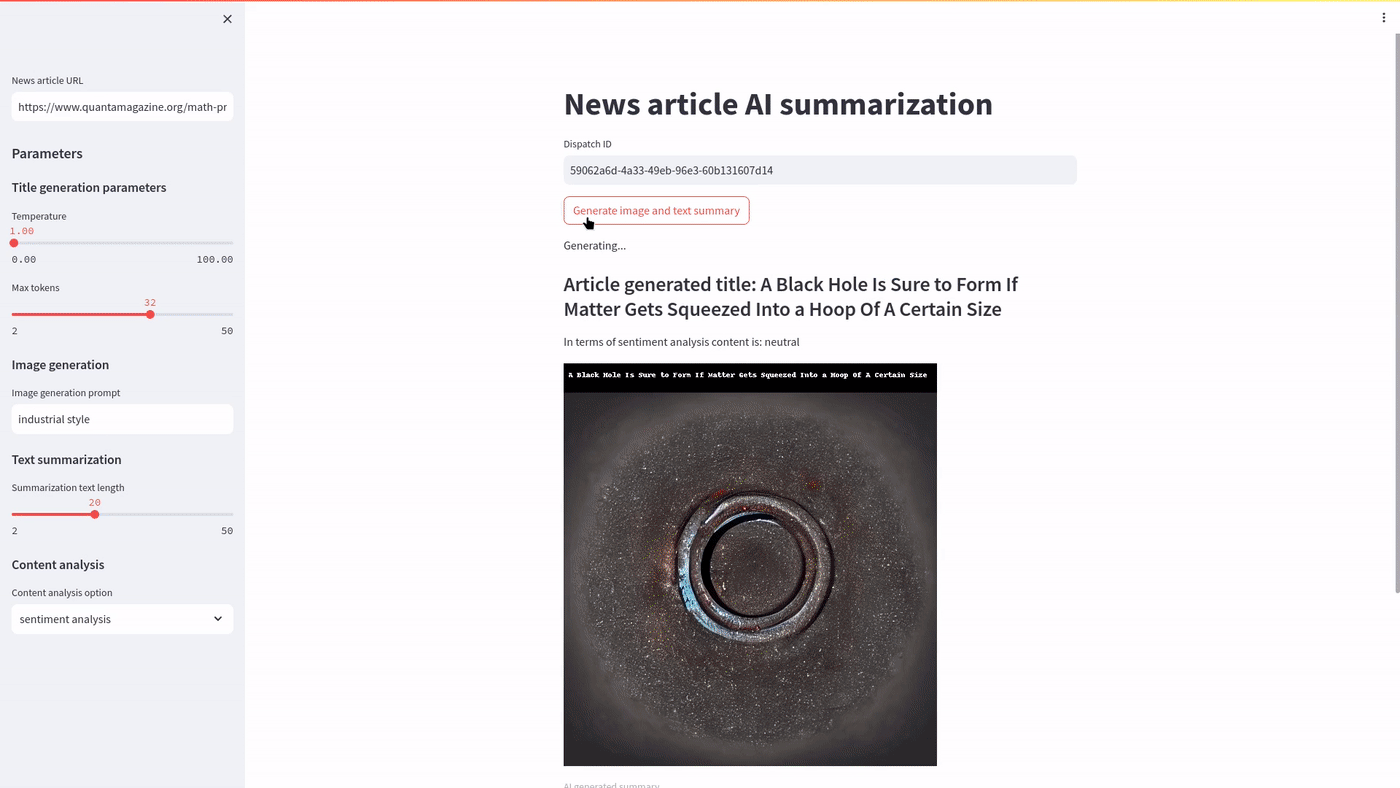
Generating multiple images with Streamlit via Covalent is demonstrated below
Conclusion#
You have learned how to build complex machine learning workflows using an example of a news summarization application. A Covalent server takes care of the machine learning workflows, while a Streamlit interface handles user interactions. The two communicate via a single (dispatch) ID, streamlining resource management, enhancing efficiency, and allowing you to concentrate on the machine learning aspects.
If you found this interesting, please note that Covalent is free and open source. Please visit the Covalent documentation for more information and many more tutorials. An example of the Streamlit application described here was deployed here. Please note it will not be able to run out of the box, since it requires having valid Azure access credentials.
Happy workflow building! 🎈